ECCV 2014
SRCNN 论文精读
从 Sparse Coding
到端到端 CNN 超分
Single Image Super-Resolution
End-to-End Mapping
Fast Feed-Forward Inference
Dong et al. · ECCV 2014 · Image Restoration
Bicubic

Sparse Coding

SRCNN ✦

$$\hat{p}=\sum_{i=-1}^{2}\sum_{j=-1}^{2}w_iw_jp_{ij}$$
数据处理不等式
X → Y → Z
I(X ; Y) ≥ I(X ; Z)
无论后续怎样处理数据,都不能添加原本不存在的信息。对应到 Bicubic:它只能重排、加权和平滑 LR 中已有的像素,不能凭空恢复降采样时丢失的高频细节。
那么,是否意味着超分辨率理论上不可能?
不一定
如果有其他信息来源,就可以用先验知识约束答案。这里引入机器学习的
Sparse Coding。
额外信息来源:训练集图像库
→
学习 LR/HR patch 对应关系
D_l
D_h
+
→
不只靠几何插值,
还利用数据先验 补细节
还利用数据先验 补细节
测试时逐 patch 求解(关键瓶颈)
\(\alpha^*=\arg\min_{\alpha}\|D_l\alpha-y\|_2^2+\lambda\|\alpha\|_1\)
\(x=D_h\alpha^*\quad(\text{HR patch 重建})\)
Dl、Dh 离线训练好 ·
但 α* 必须在测试时对每个 patch 单独迭代求解
稀疏表示原理:同一 α* 连接 LR ↔ HR 空间
从单个 patch 到整图输出:SC 的实际推理流水线
字典离线训练;真正耗时的是对每个重叠 patch 在线求稀疏编码
所以 SC 的瓶颈不是“不会重建”,而是:每个 patch 都要反复解一次稀疏优化问题
2014 年之前,CNN 在图像分类上已非常成功(AlexNet 2012)。
但分类 CNN 的整套架构是"层层压缩"——专门设计来扔掉空间细节;
而超分恰恰需要"保留并恢复空间细节",需求完全相反。甚至可以说,在SRCNN之前,卷积核的滑动更多是用于模糊图片而非清晰图片
分类 CNN 的本质:层层压缩空间,最终输出 1 个类别标签
224×224×3
输入图像
112×112×64
conv + pool
56×56×128
conv + pool
28×28×256
继续缩
7×7×512
conv + pool
FC 层
压扁拉直
猫
1000 类
输出
~15 万维像素表示 → 被层层压缩成 1 个类别标签
分类 CNN 中的"反超分"设计:三件事都在丢空间细节
池化(Pooling)
把 2×2 区域压成 1 个值
空间尺寸直接减半
空间尺寸直接减半
作用:抓"语义",不管"猫耳朵在哪个像素"
大步长卷积
stride = 2 或更大
每两格才采样一次
每两格才采样一次
作用:迅速缩小空间尺寸,扔掉局部细节
全连接层(FC)
把整张特征图压扁
变成一维向量
变成一维向量
作用:融合所有空间信息,做出一个分类决策
这正是大家"想不到用 CNN 做 SR"的原因
分类 CNN 看上去和超分需求完全相反——超分需要"保留并恢复每一个像素的位置",而分类正在拼命扔掉它。
→
SRCNN 的转念:把卷积层"拆"出来重用
"压缩属性"全在池化和 FC,纯卷积层本身是保留尺寸的——只用卷积,不用池化和 FC,就成了一个低层视觉处理器。
SRCNN paper Fig. 3
Sparse-coding-based SR in the view of CNN
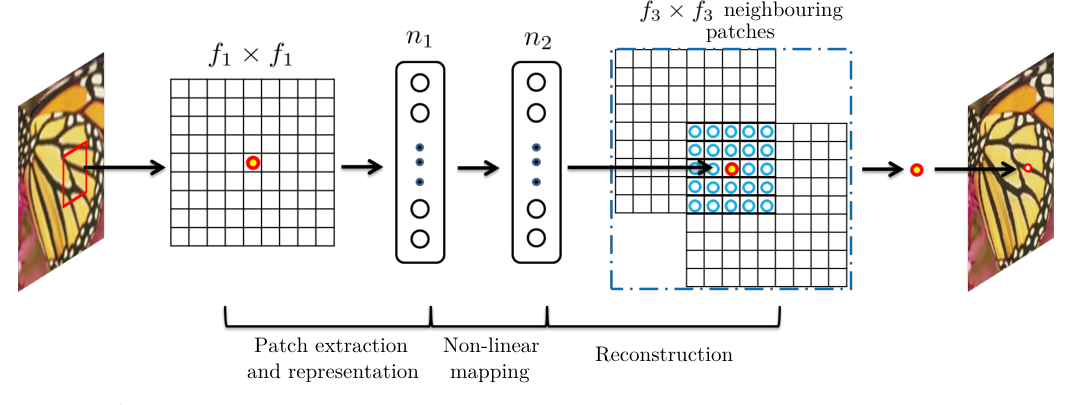
KEY POINT
SC 流程可以被 CNN 化。
红点表示我们追踪的一个最终 HR 像素:它来自一个输入 patch、一次非线性编码,以及周围多个重叠 patch 的聚合。
01 / PATCH EXTRACTION
看一个 \(f_1\times f_1\) LR patch
SC:抽 patch,再投影到 LR dictionary 得到 \(n_1\) 个响应。
SRCNN:第一层 \(9\times9\) Conv 产生 64 张 feature maps。
02 / NON-LINEAR MAPPING
\(n_1\rightarrow n_2\):稀疏求解器
传统 SC 每个 patch 都要现场求:
$$\alpha^*=\arg\min_\alpha \lVert D_l\alpha-y\rVert_2^2+\lambda\lVert\alpha\rVert_1$$
SRCNN:用 \(1\times1\) Conv + ReLU 直接前馈近似这个非线性映射。
03 / RECONSTRUCTION
\(f_3\times f_3\) neighbouring patches
一个输出红点会被多个重叠 HR patch 同时预测;SC 最后做 HR dictionary projection + averaging。
SRCNN:第三层 \(5\times5\) Conv 学会如何融合邻域预测。
Fig. 3 的作用:SC 的 patch 提取、稀疏求解、HR 重建和重叠平均,都能被卷积层吸收。
→
SRCNN 进一步把这些模块变成 \(W_1,W_2,W_3\),端到端一起训练。
$$Y\rightarrow F_1(Y)\rightarrow F_2(Y)\rightarrow F(Y)$$
$$\hat X(i,j)=W_3\cdot\mathrm{vec}(N_{5\times5}(F_2,i,j))+B_3$$
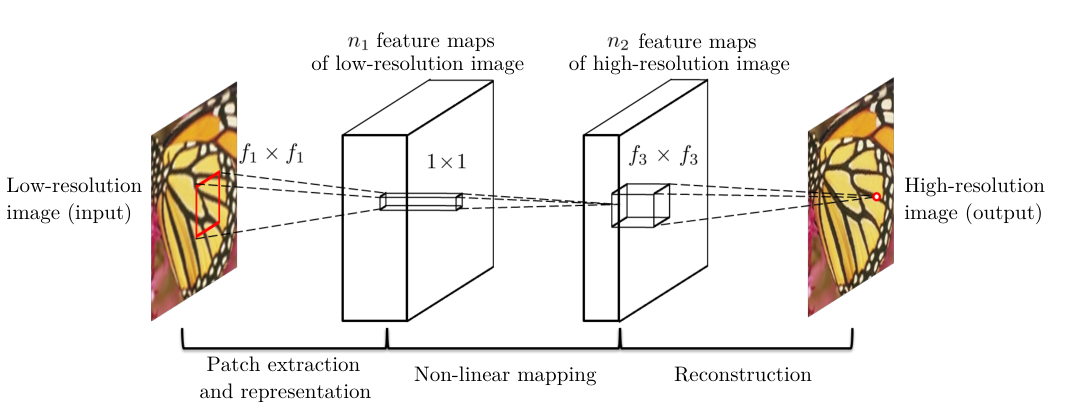
Layer 1 — Patch Extraction
$$F_1(Y)=\max(0,W_1*Y+B_1)$$
Layer 2 — Nonlinear Mapping
$$F_2(Y)=\max(0,W_2*F_1(Y)+B_2)$$
Layer 3 — Reconstruction
$$F(Y)=W_3*F_2(Y)+B_3$$
Layer 1:一个位置的 64 维响应
f₁[p] =
横向边缘强度
纵向边缘强度
45° 边缘强度
纹理响应
平滑区域响应
⋮
f₁[p] ∈ R⁶⁴:同一像素位置的一列特征响应
Layer 2:把 64 维响应重新组合
f₂[p] = ReLU(W₂ f₁[p] + b₂), W₂ ∈ R³²ˣ⁶⁴
需要锐化的边缘成分
需要补的斜线细节
某种纹理原子
⋮
从“检测到什么”变成“该补什么”。
Layer 3:邻域聚合成最终像素
→
把周围位置的 32 维表示一起看,输出最终 HR 像素;相当于把 SC 的重建和重叠平均变成可学习卷积。
滑窗扫描原理
Patch Extraction and Representation
公式与参数
$$F_1(Y)=\max(0,W_1*Y+B_1)$$
$$W_1:\underbrace{c}_{通道}\times\underbrace{f_1}_{核高}\times\underbrace{f_1}_{核宽}\times\underbrace{n_1}_{特征数}$$
$$c=1,\quad f_1=9,\quad n_1=64$$
直觉理解
- 每个位置看一个 9×9 局部 patch
- 输出一个 64 维特征向量
- 卷积核 = 学出来的局部特征检测器
- 等价于"切 patch + 线性变换 + ReLU"
参数量
5,184 weights + 64 biases
= 5,248 trainable params
通道混合原理
Non-linear Mapping(非线性映射)
公式与含义
$$F_2(Y)=\max(0,W_2*F_1(Y)+B_2)$$
$$W_2:n_1\times1\times1\times n_2 \quad (64\to32)$$
$$B_2\in\mathbb{R}^{32}$$
每个输出通道一个偏置,控制 ReLU 激活门槛
直觉理解
- 不混合邻居像素(1×1 无空间感知)
- 只混合同位置 64 个通道
- 等价于对每个像素独立应用一个小 MLP
- 近似 SC 中的 sparse coding solver
- 把 LR patch 特征翻译成 HR patch 表示
邻域聚合重建
Reconstruction(HR 重建与重叠区平均)
公式与参数
$$F(Y)=W_3*F_2(Y)+B_3$$
$$W_3:n_2\times f_3\times f_3\times c$$
$$n_2=32,\quad f_3=5,\quad c=1$$
Linear Output / 无激活函数
$$B_3\in\mathbb{R}^{c}$$
c=1(亮度图),B₃ 是一个标量偏置
对应 SC 中的操作
- 融合邻近 patch 的预测(5×5 邻域)
- HR 字典投影 + patch averaging → 可学习聚合
- 无 ReLU:最后一层保留正负残差,直接输出像素值
参数量
32 × 5 × 5 × 1 = 800 weights
+ 1 scalar bias B₃
训练样本对:从真实 HR 图像 X 构造输入 Y,再用 X 监督 F(Y;Θ)
实际训练通常裁剪大量 sub-images 作为样本
X
真实 HR
Blur
→
Downsample
→
Bicubic
→
Y
输入
SRCNN: F(Y;Θ)
forward with current parameters
F(Y)
预测 HR
↔
X
GT
Loss / Compare
F(Y;Θ)-X
训练到底得到哪些参数?
≈ 8.1K params
$$\Theta=\{W_1,W_2,W_3,b_1,b_2,b_3\}$$
LAYER 1
θ₁={W₁,b₁}
W₁: 1×9×9×64
b₁: 64
b₁: 64
学习 LR patch 的局部特征检测器
= 5,248
LAYER 2
θ₂={W₂,b₂}
W₂: 64×1×1×32
b₂: 32
b₂: 32
学习 64 → 32 的非线性通道映射
= 2,080
LAYER 3
θ₃={W₃,b₃}
W₃: 32×5×5×1
b₃: 1
b₃: 1
聚合 5×5 邻域的 32 维特征
= 801
训练循环:误差如何变成参数更新?
1 Initialize
随机初始化参数
Wᵢ~N(0,0.001²), bᵢ=0
2 Forward
当前参数生成预测
Y→F₁→F₂→F(Y)
→
3 Loss
计算与真实 HR 的误差
||F(Yᵢ;Θ)-Xᵢ||²
→
4 Backward
∇W₁ L, ∇W₂ L, ∇W₃ L
∇b₁ L, ∇b₂ L, ∇b₃ L
计算每层卷积核与 bias 的梯度
→
5 Update
Θ ← Θ − η∇_Θ L
论文使用 SGD + momentum
→
Repeat:一次次根据误差微调卷积核和 bias
MSE
\(\displaystyle L(\Theta)=\frac{1}{n}\sum_{i=1}^{n}\|F(Y_i;\Theta)-X_i\|^2\)
让 F(Y) 尽量接近 X
反向传播从哪里开始?
∂L/∂F(Y) = 2/n · (F(Y)-X)
预测结果和真实 HR 的差值,就是误差往回传的起点。
训练的本质:通过 X 与 F(Y) 的误差,反向更新 W₁,W₂,W₃,b₁,b₂,b₃。
主样本:006.jpeg
Bicubic / ScSR / SRCNN / HR

AVERAGE PSNR
32.76 dB
SRCNN 平均比 Bicubic 高 +1.71 dB,比 ScSR 高 +1.05 dB。
测试集
7 images
SRCNN 胜出
7 / 7
平均推理
372 ms
补充样本:所有对比图均来自 uploads/test
Y 通道 PSNR,边界裁掉 scale=2 像素


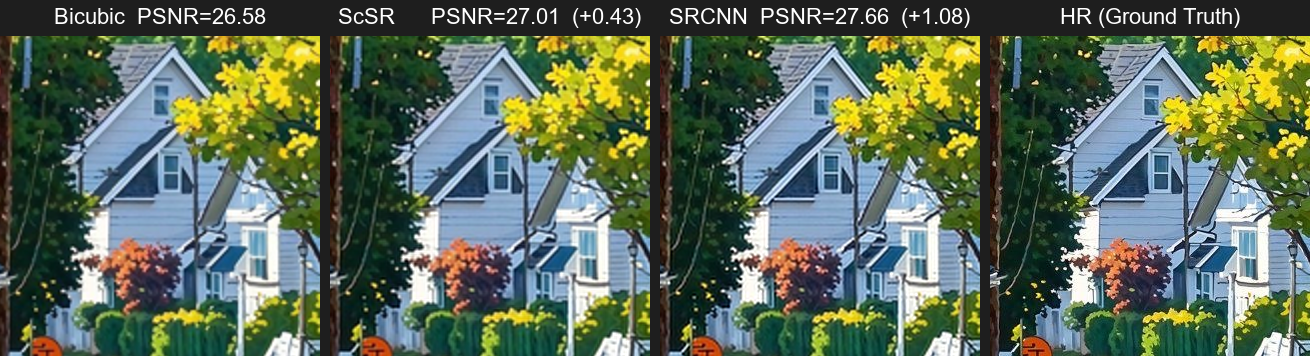



视觉上,SRCNN 的边缘和纹理更接近 HR;量化上,7 张图全部超过 Bicubic 与 ScSR。
MEAN PSNR
32.76dB SRCNN
Bicubic 31.05 · ScSR 31.71
QUALITY GAIN
+1.71dB vs Bicubic
+1.05 dB vs ScSR,且 7/7 样本领先。
SPEED
≈1600×faster
SRCNN 372 ms vs ScSR 614 s / image。
PSNR by image
灰:Bicubic · 橙:ScSR · 蓝:SRCNN
imgBicubicScSRSRCNN
00026.5426.9327.71
00129.7530.6932.08
00226.5827.0127.66
00327.3627.7528.64
00430.6631.5132.67
00537.6138.4439.84
00638.8539.6240.71
平均推理耗时
Bicubic58 ms
SRCNN372 ms
ScSR614 s
条形为非线性缩放;重点是数量级差异。
为什么 ScSR 慢?
- 每张图几十万 patch
- 每个 patch 要解 L1 稀疏优化
- SRCNN 只做一次全图前向卷积
Bicubic
无训练、毫秒级,但细节主要靠插值,PSNR 最低。
ScSR
字典学习有历史意义,但推理时逐 patch Lasso 成为瓶颈。
SRCNN
把复杂映射放到训练阶段,测试阶段只保留快速前向卷积。